How to address overfitting (beginner friendly)
Three basic methods to prevent overfitting.
 Imagine that your boss gives you some data and asks you to train a classification model. You work very hard to tune your model and finally get a well-trained model with 99% accuracy. You give this model to your boss and confidently tell him that the model is going to work well and help boost the business. Days later, your boss comes up to you and angrily shows you the horrible results when he deployed the model. You’re pretty confused about what is happening because you got 99% accuracy when you trained the model. Oh dear, that’s “overfitting”. Overfitting happens when we train a model with only training data. It fits perfectly well with training data but when the model is applied to unseen data (testing data) it performs worse. Let’s step forward to see what we can do to deal with overfitting.
Imagine that your boss gives you some data and asks you to train a classification model. You work very hard to tune your model and finally get a well-trained model with 99% accuracy. You give this model to your boss and confidently tell him that the model is going to work well and help boost the business. Days later, your boss comes up to you and angrily shows you the horrible results when he deployed the model. You’re pretty confused about what is happening because you got 99% accuracy when you trained the model. Oh dear, that’s “overfitting”. Overfitting happens when we train a model with only training data. It fits perfectly well with training data but when the model is applied to unseen data (testing data) it performs worse. Let’s step forward to see what we can do to deal with overfitting.
How to sense overfitting?
You’ve probably heard of training data and testing data thousands of times. When we train a model, we usually separate our data into a training set and testing set. Then, we use the training set to train our model and use the testing set to test the performance of our model because we need some unseen data for testing purposes to see if it’s going to work well on unseen data. Usually, if the training set has slightly better accuracy than the testing set, then the model is acceptable. We’ll say the model is trained just well. But if the training set performs way better than your testing set — let’s say you get 90% accuracy with the training set but only 60% accuracy with your testing set — then we can say the model is overfitting.
How to address overfitting?
Unfortunately, we over-trained the model, but fortunately, we have the following solutions to eradicate it:
1. Cross-Validation
This is another popular term in machine learning that many of you might be familiar with. Before, we simply separated our dataset into the training set and testing set. Now, we are going to work out with our training set. For example, we want to do a 5-fold cross-validation with the training data. First, we separate our training data evenly into 5 subsets. Each time we separate the data, we sequentially take one of the subsets out of 5 as “testing data”.
Hold on hold on, why are we making testing data again when we just made it?
The idea of cross-validation is that we tune our model with training data and while training the model we can use the “cheated” testing data to refine our model to avoid overfitting.
 2. Feature Reduction
2. Feature Reduction
A model with more features tends to make a more complicated model and the more complicated model tends to be less general. There are Principal Component Analysis (PCA) and feature selection to reduce the number of features of data. The trade-off of reducing features is that you will lose the information from your data but you will also improve the model performance.
3. Regularization
Before knowing what regularization is, you need to know what cost function is (aka loss function). The cost function is a function that calculates the error model generated. For example, in linear regression, we usually use Mean Squared Errors (MSE) as a cost function. Regularization tries to decrease or increase the weights in your model to force your model to be simpler. If the weight is near zero, it simply minimizes the effects of that feature. However, if the weight drops to zero, then it gets rid of the feature entirely. We have lasso, ridge, and elastic-net to help us do so. Let’s talk about lasso and ridge first, because they’re pretty similar and will be used for comparison. I’ll explain how to do lasso and ridge work according to its mathematical formula.
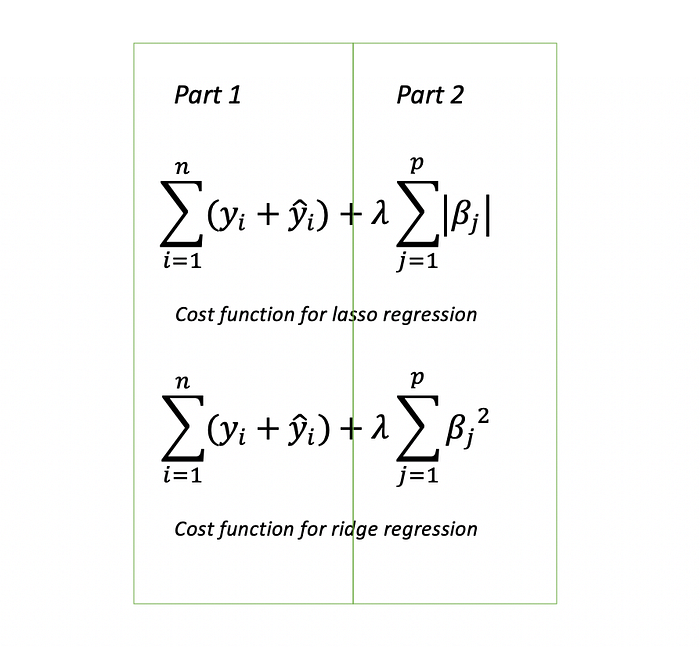
Part 1 is the original cost function for linear regression. Then, part 2 is added in the original cost function to make up a new one. When we train a model, our goal is to try to minimize cost function as little as possible because cost function represents error. Lambda is a penalty parameter which tries to penalize the weights. For example, if I choose lambda = 10000 (lambda is pretty large right now), to make the value of the whole cost function as small as possible, all weights are forced to become very small, probably 0.0001, then we successfully made our model simpler by reducing some weights in our model. But the trade-off is, if lambda is too large, then the model will become too simple. Thus, we might end up with an underfitting model or the whole function will be too focused on the penalty term and minimizing the cost function based on the penalty term.
We have to be careful when we decide lambda. The difference between lasso and ridge is that the formulas are different. The regularization term for lasso is in absolute value but the ridge is a squared value. Because of the different formulas, the results of them will also be slightly different. Both of the results will enforce weights to be smaller. Ridge will only punish weights that become smaller but won’t force them to become zero. Lasso can overcome the disadvantage of the ridge by actually setting the weights as zero if they’re not relevant, leaving the model with fewer features. In conclusion, if the model contains lots of useless variables and you want to get rid of some, then Lasso is better for regularization. If most of the variables in the model are useful and you want to keep all of them, then ridge is better for regularization.
If you want to dig inside the math to see how lasso can set weights to zero while ridge cannot, check Chetan Patil’s answer which has a good example of the math.
Lasso and ridge are only applicable when you know dataset well but what if our model includes tons of variables and it’s hard to know all of them in your data?
The variables in the model might be useful or useless. If you have no ideas about them, then an elastic net will help you out. An elastic net combines penalty terms from lasso and ridge and assigns different lambdas for them. However, the downside is that the computation is expensive.